면접이란 무엇인가라니, 상당히 뜬금없는 질문으로 느껴질 수 있다. 구직 활동에서의 면접이란, 그 사람의 역량을 확인하고 기업과 핏이 잘 맞는 사람인지를 판단하는 자리이다. 근데 이런 당연한 얘기 말고 나는 좀 다른 얘기를 하고 싶다.
필자가 다니던 이전 회사는 작은 규모의 스타트업이었다. 그러다 보니 필자가 주니어 개발자임에도 불구하고 기술면접에 들어갈 일이 종종 있었다. 난 거기서 어떻게든 면접의 분위기를 화기애애하게 만들고자, 별거 아닌 거에도 크게 웃고 리액션도 크게 했다. 내가 그렇게 한 이유는 지원자의 긴장을 풀어주기 위해서였다. 아마도 대부분의 상황에선 내가 지원자였기 때문에, 감정이입이 돼서 그렇게 한 것도 있을 것이다. 하지만 그보다 더 중요한 이유가 있었다.
아마도 회사는 인력 충원이 필요하기 때문에 사람을 뽑을 것이다. 그래서 바빠 죽겠는데도 8시간의 근무 시간 중 1~2시간(면접 시간 1시간 + 준비시간)을 할애해서 면접을 본다. 근데 만약 지원자가 긴장을 한 나머지 100이라는 실력을 가졌음에도 불구하고 50밖에 보여주지 못해서 채용하지 못한다면, 결국 시간과 돈을 땅바닥에 버린 거나 마찬가지다. 그렇기에 면접관은 어떻게 해서든 지원자가 가진 역량을 다 보여줄 수 있게 노력해야 한다고 생각한다. 그게 회사나 면접관 본인 입장에서도 이득이니까.
그리고 면접은 면접관들이 지원자를 평가하는 자리이기도 하지만, 지원자들이 회사를 평가하는 자리이기도 하다. 면접관은 전혀 그럴 의도가 아니었을 수 있지만, 면접 내내 시종일관 얼어붙은 표정을 유지하고 어둠의 기운(?)을 내뿜는다면, 지원자 입장에선 합격한다고 해도 입사가 망설여질 수밖에 없을 것이다. 결국 회사 손해고 면접관 본인 손해다.
필자가 다시 구직활동을 시작한 지 한 달 정도 되어간다. 그동안 참 많은 면접을 봤다. 그중에서 '텀블벅'이라는 회사의 기술면접이 많이 기억에 남는다. 평가를 받는 자리이기도 했지만, 선배 개발자로서 조언도 해주시는 모습이 정말 좋았다. 비록 타사 입사로 인해, 이후 프로세스는 진행하지 않기로 하였지만, 언젠가 또 인연이 될 수 있는 날이 올 거라는 생각을 해본다.
인터넷에서 제품을 구매할 땐 '재고'라는 게 있다. 근데 만약 쇼핑몰에서 10개의 상품을 준비했는데 10개 이상으로 주문이 들어오면 어떻게 될까? 그야말로 대참사다...-_- 주문 시간을 본 후 가장 마지막에 주문 한 사람들부터 차례대로 전화를 해서 사정을 얘기하고 주문 취소를 해야할 것이다... 죄 없는 고객 관리팀은 욕을 먹을 것이고, 서비스에 대한 고객들의 신뢰도는 떨어질 것이다. 물론 어떻게 해서든 상품을 더 준비하는 방법도 있겠지만, 개발자의 관점에선 저 상황이 안 오는 게 가장 좋다.
앞으로 소개할 방법은 그냥 필자가 혼자 고민하고 구글링하면서 정리한 것이다. 따라서 틀린 부분이 있을 수도 있고 실무에서 하는 방법과 다를 수도 있다. 그냥 이런 생각을 할 수도 있구나, 이런 생각을 하는 애도 있구나 정도로 참고만 하면 좋을 것 같다.
2. 단순 유효성 검사만 추가하였을 때
근데 만약 그 상품이 엄청 인기가 있는 핫한 상품이라고 가정해보자. 오픈과 동시에 1초만에 털리는 포켓몬빵과 같은... 그렇다면 거의 동시에 '재고 정보'에 접근할 가능성이 높기 때문에, 단순히 현재 재고 수량이 몇 개인지 확인한 후 주문을 넣는다면 재고량보다 많은 수의 주문이 들어올 수 밖에 없다. 아래의 코드를 보자. 예제는 최대한 단순하게 구성하였다.
@Entity
class Product(
@Column(nullable = false)
val name: String,
@Column(nullable = false)
val totalCount: Int,
stockCount: Int,
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long? = null
) {
@Column(nullable = false)
var stockCount: Int = stockCount
private set
fun applyStockCount(count: Int) {
stockCount = count
}
}
@Entity
@Table(name = "orders")
class Order(
@Column(nullable = false)
val userId: Long,
@Column(nullable = false)
val orderCount: Int,
@ManyToOne
val product: Product,
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long? = null
)
@Service
@Transactional
class OrderService(
private val orderRepository: OrderRepository,
private val productRepository: ProductRepository
) {
fun order(userId: Long, orderCount: Int, productId: Long) {
val product = productRepository.findById(productId).orElseThrow { IllegalArgumentException() }
// 주문 수량이 재고 수량보다 많은지 확인
if (product.stockCount < orderCount) {
throw IllegalArgumentException("주문 수량이 재고 수량보다 많습니다.")
}
product.decreaseStockCount(orderCount)
orderRepository.save(Order(userId, orderCount, product))
}
}
테스트 코드
이제 이 핫한 상품에 대해 동시에 많은 수의 주문이 들어오는 상황을 테스트 코드로 구현해보자. 아래 코드에는 총 1000개의 포켓몬빵이 재고로 준비되어있다. 그리고 1000명의 사용자가 2개씩 주문을 일시적으로 하는 상황이다. 정상적인 상황이라면 주문은 500개까지만 들어와야하고, 이후에는 예외가 발생해야 한다.
@SpringBootTest
internal class OrderServiceTest {
@Autowired
private lateinit var productRepository: ProductRepository
@Autowired
private lateinit var orderService: OrderService
@Test
fun 재고보다_많은_빵을_주문() {
// 1000개의 빵이 준비되어 있다.
val productId = productRepository.save(Product("포켓몬빵", 1000, 1000)).id!!
assertThatIllegalArgumentException().isThrownBy {
runBlocking {
// 1000명이 2개씩 주문
(1..1000).map {
async(Dispatchers.IO) {
orderService.order(it.toLong(), 2, productId)
}
}.awaitAll()
}
}
}
}
1000개의 주문이 생성되고, 재고 수량도 엉망으로 업데이트가 되는 결과를 예상했다. 하지만 어째서인지 데드락이 발생했다?;;; 대체 무슨 상황인지 'show engine innodb status' 명령어를 통해 확인해봤다. (필자는 DB를 mysql을 사용하였다. 일반적으로 테스트 상황에서는 h2를 사용하겠지만, 실제 프로덕션 상황과 유사한 상황을 만들기 위해서 그렇게 하였다.)
------------------------
LATEST DETECTED DEADLOCK
------------------------
2022-05-02 05:27:01 277173974784
*** (1) TRANSACTION:
TRANSACTION 5247, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 5 lock struct(s), heap size 1128, 2 row lock(s), undo log entries 1
MySQL thread id 193, OS thread handle 277724763904, query id 13000 172.17.0.1 root updating
update product set name='포켓몬빵', stock_count=975 where id=1
*** (1) HOLDS THE LOCK(S):
RECORD LOCKS space id 48 page no 4 n bits 72 index PRIMARY of table `redisson`.`product` trx id 5247 lock mode S locks rec but not gap
Record lock, heap no 2 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 8; hex 8000000000000001; asc ;;
1: len 6; hex 000000001478; asc x;;
2: len 7; hex 02000000f3086d; asc m;;
3: len 12; hex ed8facecbc93ebaaacebb9b5; asc ;;
4: len 4; hex 800003cf; asc ;;
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 48 page no 4 n bits 72 index PRIMARY of table `redisson`.`product` trx id 5247 lock_mode X locks rec but not gap waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 8; hex 8000000000000001; asc ;;
1: len 6; hex 000000001478; asc x;;
2: len 7; hex 02000000f3086d; asc m;;
3: len 12; hex ed8facecbc93ebaaacebb9b5; asc ;;
4: len 4; hex 800003cf; asc ;;
*** (2) TRANSACTION:
TRANSACTION 5250, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 5 lock struct(s), heap size 1128, 2 row lock(s), undo log entries 1
MySQL thread id 195, OS thread handle 277723707136, query id 12999 172.17.0.1 root updating
update product set name='포켓몬빵', stock_count=975 where id=1
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 48 page no 4 n bits 72 index PRIMARY of table `redisson`.`product` trx id 5250 lock mode S locks rec but not gap
Record lock, heap no 2 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 8; hex 8000000000000001; asc ;;
1: len 6; hex 000000001478; asc x;;
2: len 7; hex 02000000f3086d; asc m;;
3: len 12; hex ed8facecbc93ebaaacebb9b5; asc ;;
4: len 4; hex 800003cf; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 48 page no 4 n bits 72 index PRIMARY of table `redisson`.`product` trx id 5250 lock_mode X locks rec but not gap waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 8; hex 8000000000000001; asc ;;
1: len 6; hex 000000001478; asc x;;
2: len 7; hex 02000000f3086d; asc m;;
3: len 12; hex ed8facecbc93ebaaacebb9b5; asc ;;
4: len 4; hex 800003cf; asc ;;
두 트랜잭션이 S Lock을 가지고 있는 상황에서 서로 X Lock을 가져가려고 하니 데드락이 발생할 수 밖에 없었다. S Lock이 반환되어야 X Lock을 취할 수 있는데 X Lock을 얻기 전까진 S Lock을 반환하지 못하는 상황... 그렇다면 대체 누가 S Lock을 거는 걸까? 바로 외래키로 물려있는 order가 insert될 때 S Lock을 건다. 해결책은 2가지가 있다. 1) Order가 AI를 쓰지 않도록 하여 insert도 지연 실행되게 한다. 2) Product의 업데이트문을 Order가 insert되기 전 강제로 실행한다(saveAndFlush). 일단 이 예제에서는 2번을 택했다. 그렇게 하고 나니 1000개의 주문이 생성되고, 재고 수량도 엉망으로 업데이트가 되는 결과가 나왔다.
3. DB의 Exclusive Lock을 사용했을 때
위와 같은 상황이 발생하는 건 동시에 들어오는 요청이 재고 정보에 동시에 접근을 하기 때문에 발생하는 문제다. 그렇다면 동시에 접근을 못하게 하면 되지 않는가? 메서드 레벨에서 synchronized를 거는 방법을 생각할 수도 있겠지만, 서버를 2개 이상으로 구성을 하는 경우가 많기 때문에 적절하지 않다. 따라서 DB에 Exclusive Lock를 걸어서 이를 해결해보자. 아래와 같이 코드를 변경하였다. JPA에서 LockModeType.PESSIMISTIC_WRITE은 SELECT FOR UPDATE를 의미한다.
이제 이전의 테스트 코드를 실행하면 정상 동작하는 걸 확인할 수 있다. 그런데 DB에 매번 이렇게 X Lock을 거는 건 느리다. 필자의 컴퓨터를 기준으로 테스트 실행 시간이 약 5초 정도 소요된다. 프로덕션 코드에선 이보다 더한 병목도 발생할 수 있을 거라고 생각한다. 최적화가 필요해보인다. 그래서 쓰려고 하는게 바로 Redis이다.
4. Redisson을 이용한 Lock을 사용했을 때
Redis에도 Lock이라는 개념이 있다고 한다. 필자도 이번에 알았는데, 이를 편하게 사용할 수 있게 해주는 라이브러리가 있다. 바로 Redisson이다.
redis:
mode: SINGLE
nodes:
- 'redis://localhost:6379'
3) 코드 작성
@Component
@ConfigurationProperties("redis")
class RedisProperty {
lateinit var mode: RedisMode
lateinit var nodes: List<String>
enum class RedisMode {
SINGLE, CLUSTER
}
}
@Configuration
class RedissonConfig {
@Bean
fun redissonClient(redisProperty: RedisProperty): RedissonClient {
val config = Config().apply {
when (redisProperty.mode) {
SINGLE -> this.useSingleServer().address = redisProperty.nodes[0]
CLUSTER -> this.useClusterServers().nodeAddresses = redisProperty.nodes
}
}
return Redisson.create(config)
}
}
구현
이제 기본적인 준비는 끝났다. 이 방법에 대한 대략적인 설명을 해보도록 하겠다.
일단 각 Product별 재고 수량을 레디스에 저장한다. 그리고 레디스에서 재고 수량을 읽어와서 주문 가능 여부를 판단한다. 이때, 재고 수량을 읽고, 주문 가능 여부를 판단하고, 바뀐 재고 수량을 다시 저장하는 것까지 오직 하나의 쓰레드에서만 이루어져야한다. DB에서의 Exclusive락과 동일한 역할을 하는 레디스에서의 락을 이용하는 것이다. 레디스는 메모리 디비이기 때문에 일단 RDB에 비해서 성능이 훨씬 빠를 것이다. 아래는 이를 위해 작성한 코드들이다.
interface KeyValueStore {
fun <T> getValue(key: String): Optional<T>
fun <T> save(key: String, value: T)
fun <T> executeWithLock(key: String, function: () -> T): T
}
@Component
class RedisStore(
private val redissonClient: RedissonClient
) : KeyValueStore {
companion object {
private const val LOCK_SUFFIX = ":lock"
private const val WAIT_TIME_SECONDS = 3L
private const val LEASE_TIME_SECONDS = 3L
}
override fun <T> getValue(key: String): Optional<T> {
val bucket = redissonClient.getBucket<T>(key)
if (bucket.isExists) {
return Optional.of(bucket.get())
}
return Optional.empty()
}
override fun <T> save(key: String, value: T) {
redissonClient.getBucket<T>(key).set(value)
}
override fun <T> executeWithLock(key: String, function: () -> T): T {
val lock = redissonClient.getLock(key + LOCK_SUFFIX)
try {
lock.tryLock(WAIT_TIME_SECONDS, LEASE_TIME_SECONDS, TimeUnit.SECONDS)
return function()
} finally {
unlock(lock)
}
}
private fun unlock(lock: RLock?) {
if (lock != null && lock.isLocked) {
lock.unlock()
}
}
}
object RedisKeyResolver {
private const val KEY_DELIMITER = ":"
fun getKey(id: Any, domain: String, vararg subDomains: String): String {
return listOf(domain, *subDomains, id.toString()).joinToString(KEY_DELIMITER)
}
}
위의 코드에서 핵심이 되는 메서드는 바로 'executeWithLock' 메서드이다. lock.tryLock(WAIT_TIME_SECONDS, LEASE_TIME_SECONDS, TimeUnit.SECONDS) 부분에서 락을 획득하기 전까진 function()을 실행하지 않으며, finally 부분에서 락을 반환한다.
이제 OrderService 코드에 이를 적용해보자. 적용하기 전에 ProductRepository에 걸어놨던 X Lock을 없애는 걸 잊어선 안된다. 코드는 다음과 같다.
interface ProductRepository : JpaRepository<Product, Long>
@Service
@Transactional
class OrderService(
private val orderRepository: OrderRepository,
private val productRepository: ProductRepository,
private val keyValueStore: KeyValueStore
) {
private val logger = LoggerFactory.getLogger(this::class.java)
fun order(userId: Long, orderCount: Int, productId: Long) {
val product = productRepository.findById(productId).orElseThrow { IllegalArgumentException() }
val key = RedisKeyResolver.getKey(productId, "product", "order")
keyValueStore.executeWithLock(key) {
val stockCount = keyValueStore.getValue<Int>(key).orElseGet {
product.totalCount - orderRepository.findAllByProductId(productId).count()
}
// 주문 수량이 재고 수량보다 많은지 확인
if (stockCount < orderCount) {
logger.info("재고 수량 : ${stockCount}, 주문 수량 : $orderCount")
throw IllegalArgumentException("주문 수량이 재고 수량보다 많습니다.")
}
keyValueStore.save(key, stockCount - orderCount)
orderRepository.save(Order(userId, orderCount, product))
}
}
}
이렇게 바꾸고 다시 이전의 테스트 코드를 돌리면 X-Lock을 걸었을 때와 마찬가지로 정상 동작하는 걸 확인할 수 있다. 또한 시간도 필자의 컴퓨터에서 약 3.5초 정도 걸린다(X-Lock이었을 때 5초). 실제 프로덕션 환경에서 X-Lock에 대한 Race condition이 심해질 수록 차이는 더 벌어질 수 있다고 생각한다.
RDB 동기화
Redis의 데이터는 캐시 데이터로서 활용된다. 따라서 최종 재고 데이터를 RDB에 동기화해줄 필요가 있다. 이는 꼭 동기적으로 될 필요는 없다. 동기적으로 할 경우, X-Lock에 대한 Race Condition이 발생하여 사실상 Redis를 사용하는 이유가 없어질 것이다. 따라서 아래와 같이 동기화 전용 클래스를 생성하고, OrderService의 맨 마지막에 이를 실행해준다.
@Component
class StockCountProjector(
private val keyValueStore: KeyValueStore,
private val productRepository: ProductRepository
) {
fun project(productId: Long) {
CoroutineScope(Dispatchers.Default).launch {
projectInBackground(productId)
}
}
private fun projectInBackground(productId: Long) {
val product = productRepository.findById(productId).orElseThrow { IllegalArgumentException() }
val key = RedisKeyResolver.getKey(productId, "product", "order")
val stockCount = keyValueStore.getValue<Int>(key).orElseGet {
product.totalCount - orderRepository.findAllByProductId(productId).count()
}
if (product.stockCount != stockCount) {
product.applyStockCount(stockCount)
productRepository.save(product)
}
}
}
@Service
@Transactional
class OrderService(
private val orderRepository: OrderRepository,
private val productRepository: ProductRepository,
private val keyValueStore: KeyValueStore,
private val stockCountProjector: StockCountProjector
) {
private val logger = LoggerFactory.getLogger(this::class.java)
fun order(userId: Long, orderCount: Int, productId: Long) {
val product = productRepository.findById(productId).orElseThrow { IllegalArgumentException() }
val key = RedisKeyResolver.getKey(productId, "product", "order")
keyValueStore.executeWithLock(key) {
val stockCount = keyValueStore.getValue<Int>(key).orElseGet {
product.totalCount - orderRepository.findAllByProductId(productId).count()
}
// 주문 수량이 재고 수량보다 많은지 확인
if (stockCount < orderCount) {
logger.info("재고 수량 : ${stockCount}, 주문 수량 : $orderCount")
throw IllegalArgumentException("주문 수량이 재고 수량보다 많습니다.")
}
keyValueStore.save(key, stockCount - orderCount)
orderRepository.save(Order(userId, orderCount, product))
}
stockCountProjector.project(productId)
}
}
5. 생각해볼 점
Redis와 RDB가 하나의 트랜잭션 안에 있다면, 예외가 발생할 경우 롤백도 같이 되는가?
테스트를 해본 결과, 되지 않는다. 레디스는 롤백을 지원하지 않는다고 한다(https://redis.com/blog/you-dont-need-transaction-rollbacks-in-redis). 그렇다면 만에 하나 디비에 문제가 생겨서 익셉션이 발생하고 DB만 롤백이 된다면, 레디스와 DB 사이의 값의 간극이 생길 것이다. 지금 당장 생각나는 방법은, 레디스 저장을 맨 마지막에 하는 것이다. 더 좋은 아이디어 있으면 공유 좀 부탁드리겠습니다^^; 아무튼 그걸 반영한 코드는 아래와 같다.
@Service
@Transactional
class OrderService(
private val orderRepository: OrderRepository,
private val productRepository: ProductRepository,
private val keyValueStore: KeyValueStore,
private val stockCountProjector: StockCountProjector
) {
private val logger = LoggerFactory.getLogger(this::class.java)
fun order(userId: Long, orderCount: Int, productId: Long) {
val product = productRepository.findById(productId).orElseThrow { IllegalArgumentException() }
val key = RedisKeyResolver.getKey(productId, "product", "order")
keyValueStore.executeWithLock(key) {
val stockCount = keyValueStore.getValue<Int>(key).orElseGet {
product.totalCount - orderRepository.findAllByProductId(productId).count()
}
// 주문 수량이 재고 수량보다 많은지 확인
if (stockCount < orderCount) {
logger.info("재고 수량 : ${stockCount}, 주문 수량 : $orderCount")
throw IllegalArgumentException("주문 수량이 재고 수량보다 많습니다.")
}
// 여기 순서를 바꿈
orderRepository.save(Order(userId, orderCount, product))
keyValueStore.save(key, stockCount - orderCount)
}
stockCountProjector.project(productId)
}
}
레디스 락이 풀리는 시점과 RDB 트랜잭션이 commit 되는 시점이 다르다.
레디스 락의 경우 메서드 끝 부분에서 unlock메서드를 통해 풀지만, RDB commit은 메서드가 모두 끝난 후 실행된다. 이는 스프링의 트랜잭션이 AOP를 기반으로 동작하기 때문인데, 이 때문에 데이터가 꼬일 가능성이 아주 희박하게나마 있다. 예를 들면, 1번 쓰레드가 락을 반환하고 아직 커밋은 하기 전인 상황에서, 2번 쓰레드가 락을 얻고 난 후 재고 수량을 확인하는데 하필! 그 타이밍에 redis의 값들이 모두 날아가서 재고 수량을 RDB 기반으로 확인하려고 한다면! 데이터가 꼬일 것이다...; 아주 희박하긴 하지만 발생할 수 있는 버그이기에, 만약 프로덕션 환경에서 이런 버그가 발견된다면 재현이 어려워서 원인을 찾는 것도 정말 어려울 것이다ㅠㅠ 실제로 로그를 찍어보면, Redis가 unlock 되는 시점이 transaction commit 보다 앞서는 것을 확인할 수 있다.
Redis unlocked!!! 메세지는 필자가 락이 풀리는 시점에 추가한 로그임
레디스 락에 대한 처리도 AOP로 하는 걸 생각해서 구현해봤다. 근데 Transactional도 AOP로 구현되어 있고, 내가 구현한 AOP를 Transactional 내부에서 실행되도록 해야하는데 쉽지가 않았다. 그리고 무엇보다 느렸다. 런타임에 프록시 객체를 생성하기 때문인 걸로 보인다. 이에 대해서는 필자가 더 공부가 필요해보인다.
아무튼 그래서, 돌고 돌아 그냥 원래 함수에서 트랜잭션에 대한 처리를 하기로 했다. 처리 방법은 아래와 같다. Propagation level은 Requires_new로 설정했다. 바깥에서 온 트랜잭션을 가져다쓸 경우, 어차피 또 커밋 시점이 뒤로 미뤄질 것이기 때문이다.
package com.minseoklim.redissonpractice.util
import java.util.Optional
import java.util.concurrent.TimeUnit
import org.redisson.api.RLock
import org.redisson.api.RedissonClient
import org.slf4j.LoggerFactory
import org.springframework.stereotype.Component
import org.springframework.transaction.PlatformTransactionManager
import org.springframework.transaction.TransactionDefinition
import org.springframework.transaction.TransactionManager
import org.springframework.transaction.TransactionStatus
import org.springframework.transaction.support.DefaultTransactionDefinition
@Component
class RedisStore(
private val redissonClient: RedissonClient,
private val transactionManager: PlatformTransactionManager
) : KeyValueStore {
companion object {
private const val LOCK_SUFFIX = ":lock"
private const val WAIT_TIME_SECONDS = 3L
private const val LEASE_TIME_SECONDS = 3L
}
private val logger = LoggerFactory.getLogger(this::class.java)
override fun <T> executeWithLock(key: String, function: () -> T): T {
val lock = redissonClient.getLock(key + LOCK_SUFFIX)
// transaction start
val transaction = getTransaction()
try {
lock.tryLock(WAIT_TIME_SECONDS, LEASE_TIME_SECONDS, TimeUnit.SECONDS)
return function()
} finally {
// transaction commit
transactionManager.commit(transaction)
unlock(lock)
logger.info("Redis unlocked!!!!")
}
}
private fun getTransaction(): TransactionStatus {
val transactionDefinition = DefaultTransactionDefinition()
transactionDefinition.propagationBehavior = TransactionDefinition.PROPAGATION_REQUIRES_NEW
return transactionManager.getTransaction(transactionDefinition)
}
private fun unlock(lock: RLock?) {
if (lock != null && lock.isLocked) {
lock.unlock()
}
}
}
이 글은 https://docs.microsoft.com/en-us/azure/architecture/patterns/cqrs 을 기반으로 작성되었으나 필자의 생각과 별도의 코드가 추가되었다.
CQRS란 Command and Query Responsibility Segregation 의 약자로, 데이터 저장소로부터의 읽기와 업데이트 작업을 분리하는 패턴을 말한다. CQRS를 사용하면, 어플리케이션의 퍼포먼스, 확장성, 보안성을 극대화할 수 있다. 또한 CQRS 패턴을 통해 만들어진 시스템의 유연성을 바탕으로, 시간이 지나면서 지속적으로 시스템을 발전시켜나갈 수 있으며, 여러 요청으로부터 들어온 복수의 업데이트 명령들에 대한 충돌도 방지할 수 있다.
발생하던 문제점들
전통적인 아키텍처에서는, 데이터베이스에서 데이터를 조회하고 업데이트하는데 같은 데이터 모델이 사용되었다. 간단한 CRUD 작업에 대해서라면, 이것은 문제 없이 동작한다. 하지만 좀 더 복잡한 어플리케이션에서 이러한 접근 방식은 유지 보수를 어렵게 만들 수 있다. 예를 들면, 어플리케이션은 데이터 조회 시, 각기 다른 형태의 DTO를 반환하는 매우 다양한 쿼리들을 수행할 수 있다. 각각 다른 형태의 DTO들에 대해 객체 매핑을 하는 것은 복잡해질 수 있다. 또한 데이터를 쓰거나 업데이트를 할 때는, 복잡한 유효성 검사와 비즈니스 로직이 수행되어야 한다. 결과적으로 이 모든 걸 하나의 데이터 모델이 한다면, 너무 많은 것을 수행하는 복잡한 모델이 되는 것이다.
또한 읽기와 쓰기의 부하는 보통 같지 않다. 따라서 각각에 대해 다른 성능이 요구된다.
그밖에도 전통적인 아키텍처에서는 다음과 같은 문제점들이 있다.
읽기와 쓰기 작업에서 사용되는 데이터 표현들이 서로 일치하지 않는 경우가 많다. 그로 인해 일부 작업에서는 필요하지 않은 추가적인 컬럼이나 속성의 업데이트가 이뤄져야 한다.
동일한 데이터 세트에 대해 병렬로 작업이 수행될 때 데이터 경합이 발생할 수 있다.
정보 조회를 위해 요구되는 복잡한 쿼리로 인해 성능에 부정적인 영향을 줄 수 있다.
하나의 데이터 모델이 읽기와 쓰기를 모두 수행하기 때문에, 보안 관리가 복잡해질 수 있다. (예를 들면 사용자 데이터의 경우 비밀번호가 노출되선 안된다)
해결책
CQRS는 읽기와 쓰기를 각각 다른 모델로 분리한다. 명령(Command)을 통해 데이터를 쓰고, 쿼리(Query)를 통해 데이터를 읽는다.
명령(Command)은 데이터 중심적이 아니라 수행할 작업 중심이 되어야 한다. 예를 들면 '호텔룸의 상태를 예약됨으로 변경한다'가 아니라 '호텔 룸 예약'과 같이 생성되어야 한다.
명령(Command)은 보통 동기적으로 처리되기보단, 비동기적으로 큐에 쌓인 후 수행된다.
쿼리(Query)는 데이터 베이스를 결코 수정하지 않는다. 쿼리(Query)는 어떠한 도메인 로직도 캡슐화하지 않은 DTO만을 반환한다.
읽기/쓰기 모델들은 서로 격리될 수 있다. 이렇게 읽기/쓰기 모델을 분리하는 것은 어플리케이션 디자인과 구현을 더욱 간단하게 만들어준다. 하지만 CQRS 코드는, ORM 툴을 통해 DB 스키마로부터 자동으로 생성되도록 할 수는 없다는 단점이 있다.
좀 더 확실한 격리를 위해, 물리적으로 읽기와 쓰기를 분리할 수 있다. 예를 들면 읽기 DB의 경우, 복잡한 조인문이나 ORM 매핑을 방지하기 위해 materialized view 를 가지는, 조회에 최적화된 별도의 DB 스키마를 가질 수 있다. 단지 다른 DB 스키마가 아니라 아예 다른 타입의 데이터 저장소를 사용할 수도 있다. 예를 들면 쓰기는 RDBMS를 사용하고, 읽기의 경우 몽고디비와 같은 NoSql을 사용하는 것이다.
만약 이와 같이 별도의 읽기/쓰기 데이터 저장소가 사용된다면, 반드시 동기화가 이뤄져야 한다. 보통 이는 쓰기 모델이 DB에 수정사항이 발생할 때마다 이벤트를 발행함으로써 이뤄진다. 이때 DB 업데이트와 이벤트 발행은 반드시 하나의 트랜잭션 안에서 이뤄져야 한다.
읽기 저장소는 단순히 쓰기 저장소의 레플리카일 수도 있고, 완전히 다른 구조를 가질 수도 있다. 어찌 되었건 읽기와 쓰기를 분리하는 것은 각각의 부하에 알맞게 스케일링을 하는 것을 가능하게 해 준다. 예를 들면, 보통 읽기 저장소가 쓰기보다 훨씬 더 많은 부하를 받게 된다.
CQRS의 장점은 아래와 같다.
독립적인 스케일링 : CQRS는 읽기와 쓰기 각각에 대해 독립적으로 스케일링을 하는 것을 가능하게 해준다. 이는 훨씬 더 적은 Lock 경합이 발생하는 것을 가능하게 한다.
최적화된 데이터 스키마 : 읽기 저장소는 쿼리에 최적화된 스키마를 사용할 수 있고, 쓰기 저장소는 쓰기에 최적화된 스키마를 사용할 수 있다.
보안 : 읽기와 쓰기를 분리함으로써 보안 관리가 용이해진다.
관심사 분리 : 읽기와 쓰기에 대한 관심사 분리는, 시스템의 유지 보수를 더 쉽게 해 주고 유연하게 해 준다. 대부분의 복잡한 비즈니스 로직은 쓰기 모델에 들어가고, 상대적으로 읽기 모델은 간단해진다.
간단한 쿼리 : 읽기 저장소의 materialized view를 통해, 복잡한 조인문을 사용하지 않을 수 있다.
구현 이슈
CQRS를 구현하기 위해선 다음과 같은 어려움이 있다.
복잡성 : CQRS의 기본 아이디어는 간단하다. 하지만 이 패턴은 만약 이벤트 소싱 패턴을 포함할 경우, 더 복잡해질 수 있다.
메세징 : 메세징이 CQRS의 필수요소는 아니지만, 명령(Command)을 수행하고 업데이트 이벤트를 발행하는 것이 보편적인 사용법이다. 이 경우 어플리케이션은 반드시 메세지 실패나 중복 메세지와 같은 것들에 대한 처리를 해야 한다.
데이터 일관성 : 만약 읽기/쓰기 저장소가 분리된다면, 읽기 데이터가 최신의 데이터가 아닐 수도 있다. 읽기 저장소에는 쓰기 저장소의 변경 사항들이 반영되어야 하는데, 이에는 딜레이가 생기기 때문이다.
CQRS를 사용해야 할 때
CQRS는 다음과 같은 경우에 사용을 고려해볼 수 있다.
많은 사용자가 동일한 데이터에 병렬로 액세스하는 도메인. CQRS는 도메인 레벨에서의 병합 충돌을 최소화할 수 있도록 충분히 세분화된 명령(Command)를 정의하는 것을 가능하게 해 준다.
복잡한 프로세스나 도메인 모델을 통해 가이드되는 작업 기반 사용자 인터페이스. 쓰기 모델은 비즈니스 로직, 유효성 검사 등을 모두 가진 완전한 명령(Command) 처리 기능을 가진다. 쓰기 모델은 관련된 객체들의 집합을 하나의 단위(DDD에서의 aggregate)로 다룰 수 있고, 이 객체들이 항상 일관된 상태를 가지도록 보장할 수 있다. 읽기 모델의 경우 비즈니스 로직이나 유효성 검사 같은 것 없이, 오직 DTO만 반환한다. 읽기 모델은 최종적으로 쓰기 모델과 일치하게 된다. (딜레이는 있을 수 있음)
데이터 읽기의 성능이 데이터 쓰기의 성능과 별도로 조정이 가능해야 할 때. 특히 읽기의 수가 쓰기의 수보다 훨씬 많을 때. 이 경우, 읽기 모델은 스케일 아웃을 하고, 쓰기 모델은 적은 수로 유지할 수 있다. 적은 수의 쓰기 모델은 병향 충돌의 가능성을 최소화해준다.
한 팀은 쓰기 모델에 대한 복잡한 도메인 모델에만 집중해야 하고, 다른 한 팀은 사용자 인터페이스에 대한 읽기 모델에만 집중해야 할 때
시스템이 시간이 지남에 따라 계속해서 진화하고, 여러 버전을 가질 수 있으며, 정기적으로 바뀔 수 있는 경우
다른 시스템과의 통합, 특히 이벤트 소싱과 결합할 때. 서브시스템의 일시적 장애가 다른 시스템에 영향을 줘선 안된다.
다음과 같은 경우에는 CQRS 사용이 권장되지 않는다.
도메인과 비즈니스 로직이 간단할 때
단순한 CRUD일 때
이벤트 소싱과 CQRS 패턴
CQRS 패턴은 이벤트 소싱 패턴과 자주 같이 쓰인다. CQRS 기반 시스템은 분리된 읽기/쓰기 모델을 가지고, 이들은 각자의 작업에 최적화되어있으며 대부분 물리적으로도 다른 저장소에 위치한다. 이벤트 소싱 패턴과 CQRS를 같이 사용할 때는, 이벤트 저장소가 쓰기 모델이 되며, 이것이 메인 저장소가 된다. 읽기 모델은 일반적으로 매우 역정규화된 materialized view를 제공한다. 이 뷰들은 어플리케이션의 요구사항에 최적화되어있으며, 이로 인해 조회 성능을 극대화한다.
특정 시점의 실제 데이터를 사용하는 것 대신 쓰기 저장소로서 이벤트 스트림을 사용하는 것은, 하나의 aggregate에 대한 병합 충돌을 방지해주고 성능과 확장성을 극대화시켜준다. 이벤트들은 비동기적으로 읽기 저장소의 materialized view들을 생성하고 변경하는 데 사용된다.
이벤트 저장소가 공식 메인 저장소이기 때문에, 시스템이 변경되거나 단순히 읽기 모델이 변경되었을 때, materialized view를 삭제하고 과거의 모든 이벤트를 다시 실행하여 새로운 형태로 생성하는 것도 가능하다. materialized view는 사실상 읽기 전용 캐시라고 보면 된다.
CQRS와 이벤트 소싱을 같이 사용할 때는 다음 사항들을 고려해야 한다.
읽기/쓰기 저장소가 분리되어있는 시스템에서는, 이벤트가 실행되어 저장소가 수정되기 전 약간의 딜레이가 있을 수 있다.
이 패턴은 시스템의 복잡성을 증가시킨다. CQRS의 복잡성은 성공적인 구현을 더 어렵게 만들 수도 있다. 하지만 이벤트 소싱 방식을 사용하면 도메인 모델링을 더 쉽게 할 수도 있고, 데이터 변경 이벤트들이 보존되기 때문에 뷰들을 리빌딩하는 것도 쉽게 할 수 있다.
읽기 모델에서 materialized view를 만들어내는 데는 오랜 실행 시간이나 리소스가 필요할 수 있다. 특히 오랜 기간 동안의 데이터 합계나 분석 자료와 같은 것이 필요할 땐 더더욱 그렇다. 이럴 경우, 일정 간격으로 데이터의 스냅샷을 만들어냄으로써 (예: 특정 액션의 총합, 한 엔티티의 현재 상태) 해결할 수 있다.
예제에서는 사용자를 생성하고 수정하며, 사용자의 연락처, 주소를 조회하는 기능을 구현할 것이다. 기반이 되는 도메인 클래스는 아래와 같다.
class User(
val userId: String,
val name: String,
var contacts: MutableSet<Contact> = mutableSetOf(),
var addresses: MutableSet<Address> = mutableSetOf()
)
data class Contact(
val type: String,
val detail: String
)
data class Address(
val city: String,
val state: String,
val postalCode: String
)
CQRS는 명령(Command)과 조회(Query)를 분리함으로써, 읽기와 쓰기 모델을 분리하는 것이다. 먼저 사용자 생성과 수정에 대한 처리를 해보도록 하자.
사용자 생성/수정에 대한 명령(Command)
명령(Command)에 대한 코드는 아래와 같다. 사용자를 생성할 때 연락처와 주소를 함께 집어넣을 수도 있을 것이고, 수정 시 이름을 바꾸는 경우가 발생할 수도 있을 것이다. 하지만 이 예제에서는 아래와 같이 생성하고 수정한다고 가정해보자. 실제 비즈니스 케이스에서도 이처럼 다양한 요구사항에 대한 세분화된 명령(Command)을 생성할 수 있다.
class CreateUserCommand(
val userId: String,
val name: String
)
class UpdateUserCommand(
val userId: String,
val contacts: Set<Contact>,
val addresses: Set<Address>
)
사용자 이벤트
이 예제에서는 이벤트 소싱 패턴을 사용할 것이다. 즉, 이벤트 저장소가 쓰기 저장소인 동시에 메인 저장소가 될 것이다. 이벤트에 대한 코드는 아래와 같이 구성하였다.
abstract class Event {
val id = UUID.randomUUID()
val createdDate = LocalDateTime.now()
}
abstract class UserEvent(
val userId: String
) : Event()
class UserCreatedEvent(
userId: String,
val name: String
) : UserEvent(userId)
class UserContactAddedEvent(
userId: String,
val type: String,
val detail: String
) : UserEvent(userId)
class UserContactRemovedEvent(
userId: String,
val type: String,
val detail: String
) : UserEvent(userId)
class UserAddressAddedEvent(
userId: String,
val city: String,
val state: String,
val postalCode: String
) : UserEvent(userId)
class UserAddressRemovedEvent(
userId: String,
val city: String,
val state: String,
val postalCode: String
) : UserEvent(userId)
이 이벤트를 저장하는 EventStore라는 클래스를 아래와 같이 생성하였다. 실제 구현 시에는 카프카와 같은 MQ가 사용되겠지만, 이 예제에서는 간단하게 메모리를 사용하였다. 맵이 멀티쓰레드로부터 안전하지 않겠지만 이 예제에서는 그런 세세한 것까지 신경쓰진 않았다.
@Component
class EventStore {
// userId를 키로 가진 Map
private val userEventStore = mutableMapOf<String, MutableList<Event>>()
fun addUserEvent(event: UserEvent) {
userEventStore[event.userId]?.add(event) ?: userEventStore.put(event.userId, mutableListOf(event))
}
fun addUserEvents(events: Collection<UserEvent>) {
if (events.isNotEmpty()) {
val userId = events.first().userId
userEventStore[userId]?.addAll(events) ?: userEventStore.put(userId, ArrayList(events))
}
}
fun getUserEvents(userId: String): List<Event> {
return userEventStore[userId] ?: emptyList()
}
}
사용자 생성/수정
이벤트 소싱 패턴에서 사용자를 생성/수정한다는 것은 결국 해당 이벤트를 이벤트 저장소에 저장하는 것이 될 것이다. DDD에서 나오는 Aggregate라는 용어를 사용하여 아래와 같이 구현하였다.
UserUtility를 보면, 사용자의 현재 상태를 알기 위해 매번 모든 이벤트를 처음부터 다시 실행하는데, 실제 프로덕션 코드에서 이렇게 하면 정말 많은 부하가 생길 것이다. 보통은 정기적으로 스냅샷을 찍는다거나 RDB를 추가적으로 쓴다거나 하지 않을까... 이건 사실 실무에서 내가 안해봐서 잘 모르겠다.
@Component
class UserAggregate(
private val eventStore: EventStore
) {
fun handleCreateUserCommand(command: CreateUserCommand): List<Event> {
val event = UserCreatedEvent(command.userId, command.name)
eventStore.addUserEvent(event)
return listOf(event)
}
fun handleUpdateUserCommand(command: UpdateUserCommand): List<Event> {
val user = UserUtility.recreateUserState(eventStore, command.userId)
val events = mutableListOf<UserEvent>()
val userContactAddedEvents = command.contacts
.filter { it !in user.contacts }
.map { UserContactAddedEvent(command.userId, it.type, it.detail) }
events.addAll(userContactAddedEvents)
val userContactRemovedEvents = user.contacts
.filter { it !in command.contacts }
.map { UserContactRemovedEvent(command.userId, it.type, it.detail) }
events.addAll(userContactRemovedEvents)
val userAddressAddedEvents = command.addresses
.filter { it !in user.addresses }
.map { UserAddressAddedEvent(command.userId, it.city, it.state, it.postalCode) }
events.addAll(userAddressAddedEvents)
val userAddressRemovedEvents = user.addresses
.filter { it !in command.addresses }
.map { UserAddressRemovedEvent(command.userId, it.city, it.state, it.postalCode) }
events.addAll(userAddressRemovedEvents)
eventStore.addUserEvents(events)
return events
}
}
object UserUtility {
fun recreateUserState(store: EventStore, userId: String): User {
val events = store.getUserEvents(userId)
if (events.isEmpty() || events[0] !is UserCreatedEvent) {
throw IllegalArgumentException()
}
val userCreatedEvent = events[0] as UserCreatedEvent
val user = User(userCreatedEvent.userId, userCreatedEvent.name)
for (i in 1 until events.size) {
when (val event = events[i]) {
is UserAddressAddedEvent -> {
val address = Address(event.city, event.state, event.postalCode)
user.addresses.add(address)
}
is UserAddressRemovedEvent -> {
val address = Address(event.city, event.state, event.postalCode)
user.addresses.remove(address)
}
is UserContactAddedEvent -> {
val contact = Contact(event.type, event.detail)
user.contacts.add(contact)
}
is UserContactRemovedEvent -> {
val contact = Contact(event.type, event.detail)
user.contacts.remove(contact)
}
}
}
return user
}
}
사용자의 연락처, 주소 쿼리(Query)
사용자는 복수의 연락처들과 주소를 가지고 있다. 특정 사용자의 연락처 타입별 모든 연락처를 조회해야하는 비즈니스 요구사항이 있다고 가정해보자. (예를 들면, 휴대폰 타입의 연락처만 다 조회해와야한다.) 마찬가지로 특정 사용자의 주소 중 경기도에 속한 주소만 가져와야한다고 가정해보자. 쿼리(Query) 클래스는 아래와 같다.
class ContactByTypeQuery(
val userId: String,
val type: String
)
class AddressByStateQuery(
val userId: String,
val state: String
)
이러한 비즈니스 요구사항에서 일반적인 RDB를 쓴다면, 일단 사용자와 연락처/주소가 일대다 관계이기 때문에 별도의 테이블로 구성이 될 것이고 join문이 사용될 것이 때문에, 이에 따른 부하가 생길 것이다. CQRS는 특정 비즈니스 요구사항에 최적화된 읽기 저장소를 갖는 것을 가능하게 해준다. 실제 구현 시에는 몽고디비나 RDB의 materialized view를 사용하겠으나, 이 예제에서는 간단하게 메모리를 사용하겠다.
@Repository
class UserReadRepository {
val userContactStore = mutableMapOf<String, UserContact>()
val userAddressStore = mutableMapOf<String, UserAddress>()
fun getUserContact(userId: String): Optional<UserContact> {
return Optional.ofNullable(userContactStore[userId])
}
fun getUserAddress(userId: String): Optional<UserAddress> {
return Optional.ofNullable(userAddressStore[userId])
}
}
class UserContact(
val contactByType: MutableMap<String, MutableSet<Contact>> = mutableMapOf()
)
class UserAddress(
val addressByState: MutableMap<String, MutableSet<Address>> = mutableMapOf()
)
사용자의 연락처, 주소 조회
아래와 같이 조회할 수 있다.
@Component
class UserProjection(
private val readRepository: UserReadRepository
) {
fun handleContactByTypeQuery(query: ContactByTypeQuery): Optional<Set<Contact>> {
val userContact = readRepository.getUserContact(query.userId).orElseThrow()
return Optional.ofNullable(userContact.contactByType[query.type])
}
fun handleAddressByStateQuery(query: AddressByStateQuery): Optional<Set<Address>> {
val userAddress = readRepository.getUserAddress(query.userId).orElseThrow()
return Optional.ofNullable(userAddress.addressByState[query.state])
}
}
쓰기 저장소와 읽기 저장소 동기화
이제 쓰기 저장소의 이벤트들이 지속적으로 읽기 저장소에 동기화가 이뤄진다면, CQRS 구현 완성이다! 먼저 Event객체들을 읽기 저장소에 반영해주는 Projector 클래스를 아래와 같이 구현하였다.
@Component
class UserProjector(
private val readRepository: UserReadRepository
) {
fun project(event: Event) {
when (event) {
is UserCreatedEvent -> apply(event)
is UserContactAddedEvent -> apply(event)
is UserContactRemovedEvent -> apply(event)
is UserAddressAddedEvent -> apply(event)
is UserAddressRemovedEvent -> apply(event)
}
}
private fun apply(event: UserCreatedEvent) {
readRepository.userContactStore[event.userId] = UserContact()
readRepository.userAddressStore[event.userId] = UserAddress()
}
private fun apply(event: UserContactAddedEvent) {
val userContact = readRepository.getUserContact(event.userId).orElse(UserContact())
val contacts = userContact.contactByType[event.type] ?: mutableSetOf()
contacts.add(Contact(event.type, event.detail))
userContact.contactByType[event.type] = contacts
readRepository.userContactStore[event.userId] = userContact
}
private fun apply(event: UserContactRemovedEvent) {
val userContact = readRepository.getUserContact(event.userId).orElse(UserContact())
val contacts = userContact.contactByType[event.type] ?: mutableSetOf()
contacts.remove(Contact(event.type, event.detail))
}
private fun apply(event: UserAddressAddedEvent) {
val userAddress = readRepository.getUserAddress(event.userId).orElse(UserAddress())
val addresses = userAddress.addressByState[event.state] ?: mutableSetOf()
addresses.add(Address(event.city, event.state, event.postalCode))
userAddress.addressByState[event.state] = addresses
readRepository.userAddressStore[event.userId] = userAddress
}
private fun apply(event: UserAddressRemovedEvent) {
val userAddress = readRepository.getUserAddress(event.userId).orElse(UserAddress())
val addresses = userAddress.addressByState[event.state] ?: mutableSetOf()
addresses.remove(Address(event.city, event.state, event.postalCode))
}
}
동기화가 이뤄지는 시점은, 쓰기 저장소에 변경이 이뤄졌을 때일 것이다. 따라서 EventStore 클래스를 아래와 같이 변경하였다.
@Component
class EventStore(
private val userProjector: UserProjector
) {
private val userEventStore = mutableMapOf<String, MutableList<Event>>()
private val queue: Queue<Event> = LinkedList() // 나름 카프카처럼(?) 큐를 써봤다.
fun addUserEvent(event: UserEvent) {
userEventStore[event.userId]?.add(event) ?: userEventStore.put(event.userId, mutableListOf(event))
queue.offer(event)
project()
}
fun addUserEvents(events: Collection<UserEvent>) {
if (events.isNotEmpty()) {
val userId = events.first().userId
userEventStore[userId]?.addAll(events) ?: userEventStore.put(userId, ArrayList(events))
queue.addAll(events)
project()
}
}
fun getUserEvents(userId: String): List<Event> {
return userEventStore[userId] ?: emptyList()
}
// 백그라운드에서 비동기로 실행된다.
private fun project() {
CoroutineScope(Dispatchers.Default).launch {
while (queue.isNotEmpty()) {
val polledEvent = queue.poll()
userProjector.project(polledEvent)
}
}
}
}
통합 테스트
구현이 정상적으로 이뤄졌는지 확인하기 위해 아래와 같이 테스트 코드를 작성하였다. 'Thread.sleep(5000)' 과 같은, 테스트 코드에서는 있어서는 안되는 정말 바람직하지 않은 코드가 포함되어 있으나;; 이 예제의 목적은 CQRS & 이벤트 소싱 패턴 체험이라는 걸 기억하고 양해바란다^^;;;;
@SpringBootTest
internal class UserServiceTest {
@Autowired
private lateinit var userService: UserService
@Test
fun 통합테스트() {
val userId = "minseoklim"
사용자_생성_요청(userId, "임민석")
val contacts = setOf(Contact("휴대폰", "01012345678"), Contact("휴대폰", "01111111111"))
val addresses = setOf(Address("부천", "경기도", "1234"), Address("파주", "경기도", "0123"))
사용자_수정_요청(userId, contacts, addresses)
val newContacts = setOf(Contact("휴대폰", "01077777777"), Contact("휴대폰", "01111111111"))
val newAddresses = setOf(Address("부천", "경기도", "1234"), Address("화성", "경기도", "3232"))
사용자_수정_요청(userId, newContacts, newAddresses)
사용자_수정됨(userId, "휴대폰", newContacts, "경기도", newAddresses)
}
private fun 사용자_생성_요청(userId: String, name: String) {
userService.createUser(userId, name)
}
private fun 사용자_수정_요청(userId: String, contacts: Set<Contact>, addresses: Set<Address>) {
userService.updateUser(userId, contacts, addresses)
}
private fun 사용자_수정됨(
userId: String,
contactType: String,
newContacts: Set<Contact>,
state: String,
newAddresses: Set<Address>
) {
// 읽기 저장소 반영이 비동기로 되다보니 좀 기다려야 확인을 할 수 있음
Thread.sleep(5000)
val foundContacts = userService.getContactsByType(userId, contactType).get()
assert(foundContacts == newContacts)
val foundAddresses = userService.getAddressesByState(userId, state).get()
assert(foundAddresses == newAddresses)
}
}
필자는 잠시 휴식 기간을 가지고 이제 다시 구직 활동 중이다. 원티드를 주로 이용하는데, 필터 조건이 너무 마음에 들지 않았다. 나는 Spring + Java or Kotlin 기반의 개발을 해왔고, 다음 회사에서 프레임워크와 언어를 바꾸고 싶은 마음이 아직은 없었다. 근데 원티드에서 제공하는 필터링 기능을 이용해서 검색을 하면, 프론트엔드, PHP, Node.js 공고가 섞여서 나왔다....-_- 그 밖에도 온갖 걸려야할 것들을 일일히 누르면서 거르고 있자니... 너무 단순 반복 작업이고 개발자스럽지 않았다. 그래서 Python selenium을 이용하여 이를 자동화해보기로 했다!!
참고로 필자는 파이썬에 대해 거의 아는 게 없다. 그래서 파이썬 개발자가 보기엔 코드가 매우 우스워 보일 수도 있다;;
그리고 원티드에서 UI를 개편하거나 화면 구조를 살짝 틀어도 제대로 동작하지 않을 수 있다^^;;;
사용법은 다음과 같다.
1. 필요한 라이브러리 설치 : 터미널에서 다음 명령어를 쳐서 필요한 라이브러리를 다운 받는다. 크롬 기반으로 동작하므로 크롬은 반드시 설치되어 있어야 한다.
우리가 일반적으로 빈(Bean)이라고 생각하는 것은, 스프링 컨테이너가 시작될 때 함께 생성되고, 스프링 컨테이너가 종료될 때까지 유지되는 것이다. 이것은 스프링 빈이 기본적으로 싱글톤 스코프로 생성되기 때문이다. 스코프란 빈이 존재할 수 있는 범위를 뜻한다.
스프링은 다음과 같은 다양한 스코프를 지원한다.
1) 싱글톤 : 디폴트 스코프. 스프링 컨테이너의 시작과 종료까지 유지되는 가장 넓은 범위의 스코프이다.
2) 프로토타입 : 스프링 컨테이너는 프로토타입 빈의 생성과 의존 관계 주입까지만 관여하고, 더는 관리하지 않는 매우 짧은 범위의 스코프이다. 따라서 종료 메서드는 호출되지 않는다.
3) 웹 관련 스코프
request : 웹 요청이 들어오고 나갈 때까지 유지되는 스코프이다.
session : 웹 세션이 생성되고 종료될 때까지 유지되는 스코프이다.
application : 웹의 서블릿 컨텍스트와 같은 범위로 유지되는 스코프이다.
빈 스코프는 아래와 같이 지정할 수 있다.
@Scope("prototype")
@Component
public class NetworkClient {
}
@Configuration
class LifeCycleConfig {
@Scope("prototype")
@Bean
public NetworkClient networkClient() {
final NetworkClient networkClient = new NetworkClient();
return networkClient;
}
}
2. 프로토타입 스코프
싱글톤 스코프의 빈을 조회하면, 스프링 컨테이너는 항상 같은 인스턴스를 반환한다. 반면 프로토타입 스코프의 경우, 스프링 컨테이너는 항상 새로운 인스턴스를 생성해서 반환한다. 또한 프로토타입 스코프의 빈의 경우, 생성된 이후에는 스프링 컨테이너에 의해 관리되지 않는다는 점도 싱글톤 스코프와의 차이점이다. 따라서 종료 메서드는 호출되지 않는다.
아래 코드를 보면, 프로토타입 스코프 빈의 경우 빈을 조회할 때마다 빈의 생성과 의존 관계 주입, 초기화가 이뤄진다는 것을 확인할 수 있고, 스프링 컨테이너가 종료될 때도 destroy 메서드는 호출되지 않는 것을 볼 수 있다.
class PrototypeTest {
@Test
void prototypeBeanFind() {
ConfigurableApplicationContext ac = new AnnotationConfigApplicationContext(PrototypeBean.class);
System.out.println("find prototypeBean1");
final PrototypeBean prototypeBean1 = ac.getBean(PrototypeBean.class);
System.out.println("find prototypeBean2");
final PrototypeBean prototypeBean2 = ac.getBean(PrototypeBean.class);
assertThat(prototypeBean1).isNotSameAs(prototypeBean2);
ac.close();
}
@Scope("prototype")
static class PrototypeBean {
@PostConstruct
public void init() {
System.out.println("SingletonBean.init");
}
@PreDestroy
public void destroy() {
System.out.println("SingletonBean.destroy");
}
}
}
앞서 말했듯이 프로토타입 스코프의 빈은 해당 타입의 빈이 스프링 컨테이너에 요청될 때마다 생성된다. 헌데 싱글톤 스코프의 빈이 프로토타입의 빈을 주입 받는다면, 싱글톤 스코프의 빈이 생성되고 의존 관계가 주입되는 시점에만 프로토타입 빈이 조회될 것이고, 이후에는 계속 같은 빈이 사용될 것이다. 대부분의 경우, 개발자는 이를 의도하지 않았을 것이다. 애초에 매번 새로운 객체가 필요하기 때문에 프로토 타입으로 선언했을 것이기 때문이다.
따라서 아래와 같은 테스트 코드를 실행한다면, 테스트는 실패할 것이다.
class SingletonWithPrototypeTest1 {
@Test
void singletonClientUserPrototype() {
final AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(PrototypeBean.class, ClientBean.class);
final ClientBean clientBean1 = ac.getBean(ClientBean.class);
final int count1 = clientBean1.logic();
assertThat(count1).isEqualTo(1);
final ClientBean clientBean2 = ac.getBean(ClientBean.class);
final int count2 = clientBean2.logic();
assertThat(count2).isEqualTo(1);
ac.close();
}
@Scope("singleton")
static class ClientBean {
private final PrototypeBean prototypeBean; // 생성 시점에 주입
public ClientBean(final PrototypeBean prototypeBean) {
this.prototypeBean = prototypeBean;
}
public int logic() {
prototypeBean.addCount();
return prototypeBean.getCount();
}
}
@Scope("prototype")
static class PrototypeBean {
private int count = 0;
public void addCount() {
count++;
}
public int getCount() {
return count;
}
@PostConstruct
public void init() {
System.out.println("PrototypeBean.init " + this);
}
@PreDestroy
public void destroy() {
System.out.println("PrototypeBean.destroy");
}
}
}
4. 프로토타입 스코프 - 싱글톤 빈과 함께 사용시 Provider로 문제 해결
가장 간단한 방법은, 프로토타입의 의존 관계를 주입받지 않고 ApplicationContext에 매번 빈을 아래와 같이 요청하는 것이다. 하지만 이렇게 되면, 스프링에 종속적인 코드가 되고 단위테스트도 어려워 진다.
@Scope("singleton")
static class ClientBean {
@Autowired
private ApplicationContext ac;
public int logic() {
final PrototypeBean prototypeBean = ac.getBean(PrototypeBean.class);
prototypeBean.addCount();
return prototypeBean.getCount();
}
}
1) ObjectFactory, ObjectProvider
ObjectProvider는 지정한 빈을 컨테이너에서 대신 찾아주는 DL(Dependency Lookup) 서비스를 제공한다. 원래는 ObjectFactory만 있었는데, 여기에 편의 기능을 추가해서 ObjectProvider가 만들어졌다. 아래와 같이 사용할 수 있다.
@Scope("singleton")
static class ClientBean {
private final ObjectProvider<PrototypeBean> prototypeBeanProvider;
public ClientBean(final ObjectProvider<PrototypeBean> prototypeBeanProvider) {
this.prototypeBeanProvider = prototypeBeanProvider;
}
public int logic() {
final PrototypeBean prototypeBean = prototypeBeanProvider.getObject();
prototypeBean.addCount();
return prototypeBean.getCount();
}
}
특징
1) 스프링이 제공하는 기능을 사용하긴 하지만, 기능이 단순하므로 단위테스트를 만들거나 mock 코드를 만들기 쉬워진다.
2) 딱 필요한 DL(Dependency Lookup) 기능만 제공한다.
2) JSR-330 Provider
이 방법은 javax.inject.Provider 라는 JSR-330 자바 표준을 사용하는 방법이다. 이 방법을 사용하기 위해선 javax.inject:javax.inject:1 라이브러리를 gradle에 별도로 추가해야 한다. 아래와 같이 사용할 수 있다.
@Scope("singleton")
static class ClientBean {
private final Provider<PrototypeBean> prototypeBeanProvider;
ClientBean(final Provider<PrototypeBean> prototypeBeanProvider) {
this.prototypeBeanProvider = prototypeBeanProvider;
}
public int logic() {
final PrototypeBean prototypeBean = prototypeBeanProvider.get();
prototypeBean.addCount();
return prototypeBean.getCount();
}
}
특징
1) 자바 표준이므로 스프링이 아닌 다른 컨테이너에서도 사용할 수 있다.
2) 기능이 단순하므로 단위테스트를 만들거나 mock 코드를 만들기 쉬워진다.
3) 딱 필요한DL(Dependency Lookup) 기능만 제공한다.
4) 별도의 라이브러리가 필요하다.
5. 웹 스코프
웹 스코프는 웹 환경에서만 동작한다. 웹 스코프는 프로토타입과는 다르게, 스프링 컨테이너가 해당 스코프의 종료 시점까지 관리를 한다. 따라서 종료 메서드가 호출된다.
웹 스코프 종류
1) request : HTTP 요청 하나가 들어오고 나갈 때까지 유지되는 스코프. 각각의 HTTP 요청마다 별도의 빈 인스턴스가 생성되고 관리된다.
2) session : HTTP session 과 동일한 생명 주기를 가지는 스코프
3) application : 서블릿 컨텍스트과 동일한 생명 주기를 가지는 스코프
4) websocket : 웹 소켓과 동일한생명 주기를 가지는 스코프
6. request 스코프 예제 만들기
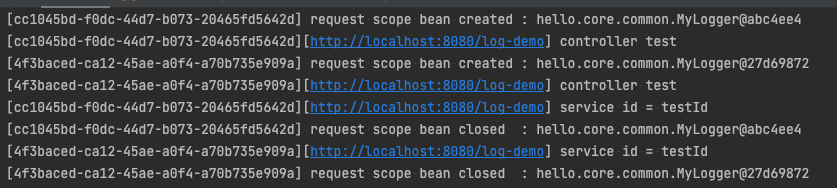
request 스코프의 경우, HTTP 요청이 들어왔을 때마다 빈이 생성되고 요청이 끝날 때까지 유지가 된다. 즉 요청이 들어왔을 때 생성이 되기 때문에, 일반적인 생성자/수정자 주입 방식 등으로 의존 관계를 주입하려고 하면 에러가 발생한다.
@Controller
@RequiredArgsConstructor
public class LogDemoController {
private final LogDemoService logDemoService;
private final ObjectProvider<MyLogger> myLoggerProvider;
@RequestMapping("/log-demo")
@ResponseBody
public String logDemo(HttpServletRequest request) throws InterruptedException {
final String requestURL = request.getRequestURL().toString();
final MyLogger myLogger = myLoggerProvider.getObject();
myLogger.setRequestUrl(requestURL);
myLogger.log("controller test");
Thread.sleep(1000);
logDemoService.logic("testId");
return "OK";
}
}
@Service
@RequiredArgsConstructor
public class LogDemoService {
private final ObjectProvider<MyLogger> myLoggerProvider;
public void logic(final String id) {
final MyLogger myLogger = myLoggerProvider.getObject();
myLogger.log("service id = " + id);
}
}
2) 프록시 사용
proxyMode를 사용하면 마치 싱글톤 스코프 빈을 주입받는 것처럼 코드를 간결하게 만들 수 있다. 적용 대상이 클래스라면 proxyMode = ScopedProxyMode.TARGET_CLASS, 인터페이스라면 proxyMode = ScopedProxyMode.INTERFACES 를 선택하면 된다.
@Controller
@RequiredArgsConstructor
public class LogDemoController {
private final LogDemoService logDemoService;
private final MyLogger myLogger;
@RequestMapping("/log-demo")
@ResponseBody
public String logDemo(HttpServletRequest request) throws InterruptedException {
final String requestURL = request.getRequestURL().toString();
myLogger.setRequestUrl(requestURL);
myLogger.log("controller test");
System.out.println("myLogger = " + myLogger);
Thread.sleep(1000);
logDemoService.logic("testId");
return "OK";
}
}
@Service
@RequiredArgsConstructor
public class LogDemoService {
private final MyLogger myLogger;
public void logic(final String id) {
myLogger.log("service id = " + id);
}
}
프록시 모드를 사용하면, 스프링은 CGLIB이라는 라이브러리를 이용하여, 내 클래스를 상속 받은 프록시 객체를 만들어서 주입한다. 따라서 스프링 컨테이너가 생성되고 빈의 의존 관계를 주입할 때, 프록시 객체가 주입되는 것이다.
가짜 프록시 객체는, HTTP 요청이 들어왔을 때 내부에서 진짜 빈을 요청하는 위임 로직을 가지고 있다. 프록시 객체는 원본 클래스를 상속해서 만들어졌기 때문에, 이 객체를 사용하는 클라이언트 입장에서는 원본인지 아닌지 모르게 동일하게 사용할 수 있다.
주의점
1) 마치 싱글톤을 사용하는 것 같지만 다르게 동작하기 때문에 주의해서 사용해야 한다.
2) 이런 특별한 scope는 꼭 필요한 곳에만 최소화해서 사용하자. 무분별하게 사용하면 유지보수하기 어려워진다.
데이터베이스 커넥션 풀이나, 네트워크 소켓과 같은 것들은 애플리케이션 시작 시점에 필요한 연결을 미리 해두고, 애플리케이션 종료 시점에 연결을 모두 종료할 필요가 있다. 아래의 NetworkClient라는 클래스에서 connect()를 통해 미리 연결을 하고, disconnect()를 통해 연결을 종료한다고 가정해보자.
public class NetworkClient {
private String url;
public NetworkClient() {
System.out.println("생성자 호출, url = " + url);
connect();
call("초기화 연결 메세지");
}
public void setUrl(final String url) {
this.url = url;
}
// 서비스 시작 시 호출
public void connect() {
System.out.println("connect: " + url);
}
public void call(String message) {
System.out.println("call: " + url + " message = " + message);
}
// 서비스 종료 시 호출
public void disconnect() {
System.out.println("close: " + url);
}
}
NetworkClient를 통해 아래와 같은 테스트 코드를 작성하여 실행해보면, url이 모두 null이 나오는 걸 확인할 수 있다. 이는 사실 당연한 결과이다. setUrl을 통해 url을 지정하기 때문에, 객체 생성 시점에는 url이 null이기 때문이다.
class BeanLifeCycleTest {
@Test
void lifeCycleTest() {
ConfigurableApplicationContext ac = new AnnotationConfigApplicationContext(LifeCycleConfig.class);
final NetworkClient client = ac.getBean(NetworkClient.class);
ac.close();
}
@Configuration
static class LifeCycleConfig {
@Bean
public NetworkClient networkClient() {
final NetworkClient networkClient = new NetworkClient();
networkClient.setUrl("http://hello.dev");
return networkClient;
}
}
}
스프링 빈은 다음과 같은 순서로 생성이 된다.
스프링 컨테이너 생성 -> 스프링 빈 생성 -> 의존 관계 주입
스프링 빈은 객체가 생성되고 의존 관계가 모두 주입이 된 이후에야 필요한 데이터를 사용할 준비가 완료된다. 따라서 초기화 작업은 의존 관계 주입이 모두 끝난 이후에 호출되어야 한다. 그런데 개발자는 의존 관계 주입이 끝난 시점을 어떻게 알 수 있을까?
스프링은 의존관계 주입이 완료되면, 스프링 빈에게 콜백 메서드를 통해 초기화 시점을 알려주는 다양한 기능을 제공한다. 또한 스프링 컨테이너가 종료되기 직전에 대한 소멸 콜백 기능도 제공한다. 따라서 개발자는 이를 이용하여 초기화와 소멸을 구현할 수 있다. 이를 포함한 스프링 빈의 라이프 사이클은 다음과 같다
스프링 컨테이너 생성 -> 스프링 빈 생성 -> 의존 관계 주입 -> 초기화 콜백 -> 사용 -> 소멸 전 콜백 -> 스프링 종료
* 참고 : 객체의 생성과 초기화를 분리하자.
사실 생성자를 통한 의존 관계 주입을 이용하면, 스프링 빈이 생성되면서 의존 관계도 같이 주입이 되기 때문에, 이 때 초기화를 할 수도 있다. 근데 만약 초기화 작업에 외부 커넥션 연결 등과 같은 무거운 동작이 포함되어 있다면, 생성자가 너무 많은 책임을 가지게 된다. 이는 SRP에 위배되고, 이보다는 객체의 생성과 초기화 부분을 명확하게 분리하는 것이 유지 보수 관점에서 좋다. 물론 내부 값들만 약간 변경하는 단순한 초기화의 경우, 생성자에서 한 번에 처리하는 게 나을 수도 있다.
스프링은 크게 3가지 방법으로 빈 생명주기 콜백을 지원한다.
1) 인터페이스(InitializingBean, DisposableBean)
2) 설정 정보에 초기화 메서드, 종료 메서드 지정
3) @PostConstruct, @PreDestroy 애노테이션 지원
2. 인터페이스(InitializingBean, DisposableBean)
아래와 같이 NetworkClient 클래스가 InitializingBean, DisposableBean 인터페이스를 구현하도록 한 후, afterPropertiesSet()에서 초기화를, destroy()에서 소멸 로직을 넣어주면 된다.
public class NetworkClient implements InitializingBean, DisposableBean {
private String url;
public NetworkClient() {
System.out.println("생성자 호출, url = " + url);
}
public void setUrl(final String url) {
this.url = url;
}
// 서비스 시작 시 호출
public void connect() {
System.out.println("connect: " + url);
}
public void call(String message) {
System.out.println("call: " + url + " message = " + message);
}
// 서비스 종료 시 호출
public void disconnect() {
System.out.println("close: " + url);
}
@Override
public void afterPropertiesSet() {
System.out.println("NetworkClient.afterPropertiesSet");
connect();
call("초기화 연결 메세지");
}
@Override
public void destroy() {
System.out.println("NetworkClient.destroy");
disconnect();
}
}
class BeanLifeCycleTest {
@Test
void lifeCycleTest() {
ConfigurableApplicationContext ac = new AnnotationConfigApplicationContext(LifeCycleConfig.class);
final NetworkClient client = ac.getBean(NetworkClient.class);
ac.close();
}
@Configuration
static class LifeCycleConfig {
@Bean
public NetworkClient networkClient() {
final NetworkClient networkClient = new NetworkClient();
networkClient.setUrl("http://hello.dev");
return networkClient;
}
}
}
인터페이스 방식의 단점
1) 이 인터페이스들은 스프링 전용 인터페이스이다. 해당 코드가 스프링 전용 인터페이스에 의존하게 된다. 물론 스프링으로 개발하면서 아예 스프링에 의존적이지 않을 수는 없겠지만 인터페이스까지 의존하는 건 좀 부담된다.
2) 초기화, 종료 메서드 명을 변경할 수 없다.
3) 내가 코드를 고칠 수 없는 외부 라이브러리들에 적용할 수 없다.
따라서 이 방법들은 지금은 거의 사용되지 않는다고 한다.
3. 설정 정보에 초기화 메서드, 종료 메서드 지정
설정 정보에 @Bean(initMethod = "init", destroyMethod = "close")와 같이 초기화, 종료 메서드를 지정해줄 수 있다.
public class NetworkClient {
private String url;
public NetworkClient() {
System.out.println("생성자 호출, url = " + url);
}
public void setUrl(final String url) {
this.url = url;
}
// 서비스 시작 시 호출
public void connect() {
System.out.println("connect: " + url);
}
public void call(String message) {
System.out.println("call: " + url + " message = " + message);
}
// 서비스 종료 시 호출
public void disconnect() {
System.out.println("close: " + url);
}
public void init() {
System.out.println("NetworkClient.init");
connect();
call("초기화 연결 메세지");
}
public void close() {
System.out.println("NetworkClient.close");
disconnect();
}
}
class BeanLifeCycleTest {
@Test
void lifeCycleTest() {
ConfigurableApplicationContext ac = new AnnotationConfigApplicationContext(LifeCycleConfig.class);
final NetworkClient client = ac.getBean(NetworkClient.class);
ac.close();
}
@Configuration
static class LifeCycleConfig {
@Bean(initMethod = "init", destroyMethod = "close")
public NetworkClient networkClient() {
final NetworkClient networkClient = new NetworkClient();
networkClient.setUrl("http://hello.dev");
return networkClient;
}
}
}
설정 정보 방식의 특징
1) 메서드 이름을 자유롭게 할 수 있다.
2) 스프링 빈 클래스가 스프링 코드에 의존하지 않는다.
3) 코드가 아닌 설정 정보를 이용하기 때문에, 코드를 고칠 수 없는 외부 라이브러리에도 적용이 가능하다.
종료 메서드 추론
@Bean의 destroyMethod 속성에는 특별한 기능이 있는데, 바로 종료 메서드 추론 기능이다. 라이브러리는 대부분 close()나 shutdown()을 종료 메서드로서 가진다. 따라서 특별히 종료 메서드를 지정해주지 않으면, 알아서 close나 shutdown이라는 메서드를 자동으로 호출해준다. 참고로 destroyMethod의 디폴트 값은 (inferred)로 등록되어 있다.
4. @PostConstruct, @PreDestroy 애노테이션 지원
초기화 메서드와 종료 메서드 앞에 각각 @PostConstruct, @PreDestroy를 붙여주면 되는 아주 간단한 방법이다.
public class NetworkClient {
private String url;
public NetworkClient() {
System.out.println("생성자 호출, url = " + url);
}
public void setUrl(final String url) {
this.url = url;
}
// 서비스 시작 시 호출
public void connect() {
System.out.println("connect: " + url);
}
public void call(String message) {
System.out.println("call: " + url + " message = " + message);
}
// 서비스 종료 시 호출
public void disconnect() {
System.out.println("close: " + url);
}
@PostConstruct
public void init() {
System.out.println("NetworkClient.init");
connect();
call("초기화 연결 메세지");
}
@PreDestroy
public void close() {
System.out.println("NetworkClient.close");
disconnect();
}
}
애노테이션 방식의 특징
1) 최신 스프링에서 가장 권장하는 방법이다.
2) 애노테이션 하나만 붙이면 되므로 매우 편리하다.
3) 패키지를 보면, 'javax.annotation.PostConstruct'이다. 이는 스프링에 종속적인 기술이 아니라 JSR-250이라는 자바 표준이다. 따라서 스프링이 아닌 다른 컨테이너에서도 잘 동작한다.
4) 컴포넌트 스캔과 잘 어울린다.
5) 유일한 단점은 외부 라이브러리에는 적용할 수 없다는 것이다. 따라서 외부 라이브러리의 경우, @Bean의 기능을 사용하자.
5. 정리
@PostConstruct, @PreDestroy 애노테이션을 사용하자
코드를 고칠 수 없는 외부 라이브러리에 대한 경우에는 @Bean의 initMethod, destroyMethod를 사용하자.
생성자를 통해서 의존 관계를 주입하는 방법이다. 이것은 생성자 호출 시점에 딱 한 번만 주입되는 것이 보장 된다. 따라서 이는 불변 의존 관계를 보장할 수 있다(단, setter가 없어야 한다.). 생성자에 파라미터가 넘어와야하기 때문에 필수 의존 관계에도 사용된다.
@Component
public class MemberServiceImpl implements MemberService {
private final MemberRepository memberRepository;
@Autowired // 생성자가 1개일 때는 Autowired 생략 가능
public MemberServiceImpl(final MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
}
2) 수정자 주입(setter 주입)
setter를 통해 의존 관계를 주입하는 방법이다. 의존 관계를 런타임에 선택하거나 변경해야하는 상황일 때 사용된다.
@Component
public class MemberServiceImpl implements MemberService {
private MemberRepository memberRepository;
@Autowired
public void setMemberRepository(final MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
}
3) 필드 주입
필드에 그대로 의존 관계를 주입하는 방법이다. 이전에는 많이 사용되던 방법이나, 스프링 없이 테스트 코드를 작성할 때 의존 관계를 설정해줄 수 없다는 단점이 있다. 그래도 요즘은 안티 패턴으로 여겨진다. 단 테스트 코드에서는 사용해도 된다.
@Component
public class MemberServiceImpl implements MemberService {
@Autowired
private final MemberRepository memberRepository;
}
4) 일반 메서드 주입
일반 메서드를 통해서 의존 관계를 주입하는 방법이다. 일반적으로는 거의 사용되지 않는다.
@Component
public class OrderServiceImpl implements OrderService {
private MemberRepository memberRepository;
private DiscountPolicy discountPolicy;
@Autowired
public void init(MemoryMemberRepository memberRepository, DiscountPolicy discountPolicy) {
this.memberRepository = memberRepository;
this.discountPolicy = discountPolicy;
}
}
2. 옵션 처리
주입할 스프링 빈이 없어도 동작해야 할 때가 있다. 그런데 @Autowired만 사용하면, required 옵션의 기본값이 true이기 때문에 오류가 발생한다. 자동으로 의존 관계를 주입할 대상을 옵션으로 처리할 수 있는 방법은 다음과 같다.
1) @Autowired(required = false) : 자동 주입할 대상이 없으면, 수정자 메서드가 호출되지 않음
2) org.springframework.lang.@Nullable : 자동 주입할 대상이 없으면, null이 입력된다.
3) Optional<> : 자동 주입할 대상이 없으면, Optional.empty()가 입력된다.
class AutowiredTest {
@Test
void autowiredOption() {
ApplicationContext ac = new AnnotationConfigApplicationContext(TestBean.class);
}
static class TestBean {
@Autowired(required = false) // Member 타입의 빈이 없을 경우, 아예 호출이 안됨
public void setNoBean1(Member noBean1) {
System.out.println("noBean1 = " + noBean1);
}
@Autowired // Member 타입의 빈이 없을 경우, null이 들어감
public void setNoBean2(@Nullable Member noBean2) {
System.out.println("noBean2 = " + noBean2);
}
@Autowired // Member 타입의 빈이 없을 경우, Optional.empty()가 들어감
public void setNoBean3(@Nullable Optional<Member> noBean3) {
System.out.println("noBean3 = " + noBean3);
}
}
}
3. 생성자 주입을 선택해라!
과거에는 setter 주입과 필드 주입도 많이 사용하였지만, 최근에는 스프링을 포함한 DI 프레임워크 대부분이 생성자 주입을 권장한다. 그 이유는 다음과 같다.
1) 불변
대부분의 의존 관계 주입은 한 번 일어나면, 애플리케이션 종료 시점까지 의존 관계를 변경할 일이 없다. 오히려 대부분의 의존 관계는 애플리케이션 종료 전까지 변하면 안된다.
수정자 주입을 사용하면, setXxx 메서드를 public으로 열어둬야하는데, 누군가 실수로 변경할 수도 있기 때문에 이는 좋은 설계가 아니다.
생성자 주입은 객체를 생성할 때 딱 1번만 호출되므로, 이후에 호출될 일은 없다. 따라서 불변하게 설계할 수 있다.
2) 누락
만약 아래와 같이 수정자 주입을 사용한다면, 테스트 코드를 작성할 때 의존 관계를 누락시킬 가능성이 있다. 하지만 생성자를 통한 주입을 사용하여 기본 생성자를 제공하지 않는다면, 의존 관계를 누락시킬 수가 없다.
@Component
public class OrderServiceImpl implements OrderService {
private MemberRepository memberRepository;
private DiscountPolicy discountPolicy;
@Override
public Order createOrder(final Long memberId, final String itemName, final int itemPrice) {
final Member member = memberRepository.findById(memberId);
final int discountPrice = discountPolicy.discount(member, itemPrice);
return new Order(memberId, itemName, itemPrice, discountPrice);
}
@Autowired
public void setMemberRepository(final MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
@Autowired
public void setDiscountPolicy(final DiscountPolicy discountPolicy) {
this.discountPolicy = discountPolicy;
}
}
class OrderServiceImplTest {
@Test
void createOrder() {
OrderServiceImpl orderService = new OrderServiceImpl();
orderService.createOrder(1L, "itemA", 10000);
}
}
3) final 키워드
생성자 주입을 사용하면, 필드에 final 키워드를 사용할 수 있다. 이를 통해 의존 관계가 바뀌지 않음을 보장할 수 있고, 혹시라도 값이 설정되지 않는 오류를 컴파일 시점에 막아줄 수 있다.
@Component
public class OrderServiceImpl implements OrderService {
private final MemberRepository memberRepository;
private final DiscountPolicy discountPolicy;
@Autowired
public OrderServiceImpl(final MemberRepository memberRepository, final DiscountPolicy discountPolicy) {
this.memberRepository = memberRepository;
this.discountPolicy = discountPolicy;
}
}
4) 정리
항상 생성자 주입을 선택하자. 그리고 가끔 옵션이 필요하면 수정자 주입을 사용하자. 필드 주입은 사용하지 않는 게 좋다.
4. 같은 타입의 빈이 2개 이상일 때
@Autowired는 타입에 의해 빈을 조회한다. 근데 만약 아래와 같이 타입의 빈이 2개 이상일 때는 어떻게 해야할까?
하위 타입으로 지정해서 빈을 주입할 수도 있겠지만 이는 DIP를 위배하고 유연성이 떨어진다. 또한 완전히 같은 타입의 2개 이상의 빈이 있는 경우도 있을 것이다.
@Component
public class FixDiscountPolicy implements DiscountPolicy {
}
@Component
public class RateDiscountPolicy implements DiscountPolicy {
}
해결 방법은 다음과 같다.
1) @Autowired 필드 명 매칭
@Autowired는 타입 매칭을 시도하고, 이때 여러 개의 빈이 있을 경우, 필드 명, 파라미터 명으로 빈 이름을 추가 매칭한다. 아래와 같이 필드명 혹은 파라미터 명을 빈 이름과 같게해줄 경우, 그 빈을 주입한다.
@Component
public class OrderServiceImpl implements OrderService {
private final MemberRepository memberRepository;
private final DiscountPolicy discountPolicy;
public OrderServiceImpl(final MemberRepository memberRepository, final DiscountPolicy rateDiscountPolicy) {
this.memberRepository = memberRepository;
this.discountPolicy = rateDiscountPolicy;
}
}
2) @Qualifier 사용
@Qualifier 는 추가 구분자를 붙여주는 방법이다. 빈 이름이 변경되지는 않는다.
@Component
@Qualifier("fixDiscountPolicy")
public class FixDiscountPolicy implements DiscountPolicy {
}
@Component
@Qualifier("mainDiscountPolicy")
public class RateDiscountPolicy implements DiscountPolicy {
}
@Component
public class OrderServiceImpl implements OrderService {
private final MemberRepository memberRepository;
private final DiscountPolicy discountPolicy;
public OrderServiceImpl(final MemberRepository memberRepository, @Qualifier("mainDiscountPolicy") final DiscountPolicy discountPolicy) {
this.memberRepository = memberRepository;
this.discountPolicy = discountPolicy;
}
}
3) @Primary 사용
@Primary는 우선 순위를 정하는 방법이다. @Autowired에 의해 여러 빈이 매칭이 되면, @Primary 를 갖는 빈이 우선권을 갖는다.
@Component
public class FixDiscountPolicy implements DiscountPolicy {
}
@Component
@Primary
public class RateDiscountPolicy implements DiscountPolicy {
}
@Component
public class OrderServiceImpl implements OrderService {
private final MemberRepository memberRepository;
private final DiscountPolicy discountPolicy;
public OrderServiceImpl(final MemberRepository memberRepository, final DiscountPolicy discountPolicy) {
this.memberRepository = memberRepository;
this.discountPolicy = discountPolicy;
}
}
5. 조회한 빈이 모두 필요할 때, List, Map
같은 타입의 빈이 모두 필요할 때는 아래와 같이 List 또는 Map으로 모든 빈들을 주입받을 수 있다. Map의 경우, key는 빈의 이름이다.
class DiscountService {
private final Map<String, DiscountPolicy> policyMap;
private final List<DiscountPolicy> policies;
public DiscountService(final Map<String, DiscountPolicy> policyMap, final List<DiscountPolicy> policies) {
this.policyMap = policyMap;
this.policies = policies;
}
public int discount(final Member member, final int price, final String discountCode) {
final DiscountPolicy discountPolicy = policyMap.get(discountCode);
return discountPolicy.discount(member, price);
}
}
6. 자동, 수동의 올바른 실무 운영 기준
그러면 어떤 경우에 컴포넌트 스캔을 활용한 자동 주입을 사용하고, 어떤 경우에 별도의 설정 정보를 통해 수동으로 빈을 등록하고, 의존 관계도 수동으로 주입해야 할까?
스프링이 나오고 시간이 갈 수록 점점 자동을 선호하는 추세다. 수동으로 설정 정보를 관리하면 매번 @Bean을 적고, 객체를 생성하고, 주입할 대상을 적어줘야하는 번거로운 작업을 해줘야한다. 그렇다면 언제 수동 빈 등록을 사용하는 것이 좋을까?
애플리케이션은 크게 업무 로직과 기술 지원 로직으로 나눌 수 있다.
업무 로직 빈 : 웹을 지원하는 컨트롤러, 비즈니스 로직이 있는 서비스, 데이터 계층의 로직을 처리하는 리포지토리 등이 모두 업무 로직이다. 이 로직들은 숫자도 매우 많고 대부분 유사한 패턴으로 개발된다. 따라서 자동 기능을 적극 사용하는 것이 좋다.
기술 지원 빈 : 기술적인 문제나 공통 관심사(AOP)를 처리할 때 주로 사용된다. 데이터베이스 연결이나, 공통 로그 처리와 같이 업무 로직을 지원하기 위한 하부 기술이나 공통 기술들에 대한 것이다. 이들은 업무 로직에 비해 그 수가 매우 적고, 애플리케이션 전반에 걸쳐 광범위하게 영향을 미치는 경우가 많다. 따라서 이런 기술 지원 로직 빈들의 경우, 가급적 수동으로 빈을 등록해서 명확하게 드러내는 것이 좋다.
업무 로직 빈이라고 하더라도, 다형성을 적극 활용하는 경우 수동으로 빈을 등록하고 관리하는 것이 더 유리할 수도 있다. 아래와 같이 관리하면, 한 눈에 관련 빈들을 확인할 수 있기 때문이다.
@Configuration
public class DiscountConfig {
@Bean
public DiscountPolicy rateDiscountPolicy() {
return new RateDiscountPolicy();
}
@Bean
public DiscountPolicy fixDiscountPolicy() {
return new FixDiscountPolicy();
}
}